Oral Presentation at MMSP 2020
Abstract
A fairly straightforward approach for music source separation is to train independent models, wherein each model is dedicated for estimating only a specific source. Training a single model to estimate multiple sources generally does not perform as well as the independent dedicated models. However, Conditioned U-Net (C-U-Net) uses a control mechanism to train a single model for multi-source separation and attempts to achieve a performance comparable to that of the dedicated models. We propose a multi-channel U-Net (M-U-Net) trained using a weighted multi-task loss as an alternative to the C-U-Net. We investigate two weighting strategies for our multi-task loss: 1) Dynamic Weighted Average (DWA), and 2) Energy Based Weighting (EBW). DWA determines the weights by tracking the rate of change of loss of each task during training. EBW aims to neutralize the effect of the training bias arising from the difference in energy levels of each of the sources in a mixture. Our methods provide two-fold advantages compared to the C- U-Net: 1) Fewer effective training iterations per epoch with no conditioning, and 2) Fewer trainable network parameters (no control parameters). Our methods achieve performance comparable to that of C-U-Net and the dedicated U-Nets at a much lower training cost.
Overview
In this work, we train a single M-U-Net for multi-instrument source separation using a weighted multi-task loss function. We investigate the source separation task in two settings: 1) singing voice separation (two sources), and 2) multi- instrument source separation (four sources). The number of final output channels of our U-Net corresponds to the total number of sources in the chosen setting. Each loss term in our multi-task loss function corresponds to the loss on the respective source estimates. We explore Dynamic Weighted Average (DWA) and Energy Based Weighting (EBW) strategies to determine the weights for our multi-task loss function. We compare the performance of our U-Net trained with the multi-task loss with that of dedicated U-Nets and the C-U-Net. Then we investigate the effect of training with the silent-source samples on the performance. We also study the effect of the choice of loss term definition on the source separation performance. Please check the full paper for more details.
Audio Examples
Examples from Singing Voice Separation Experiments
Example 1
Mix
Example 2
Mix
Examples from Multi-instrument Source Separation Experiments
Example 1
Mix
Example 2
Mix
Results
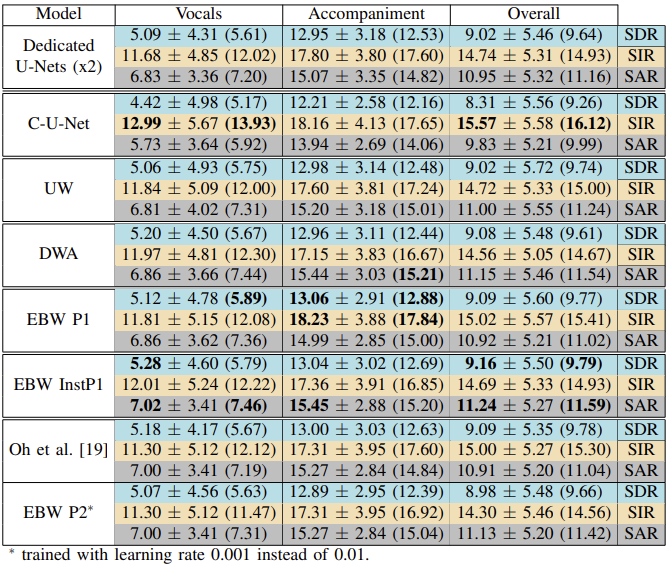
Table I. Results of Singing Voice Separation Experiments
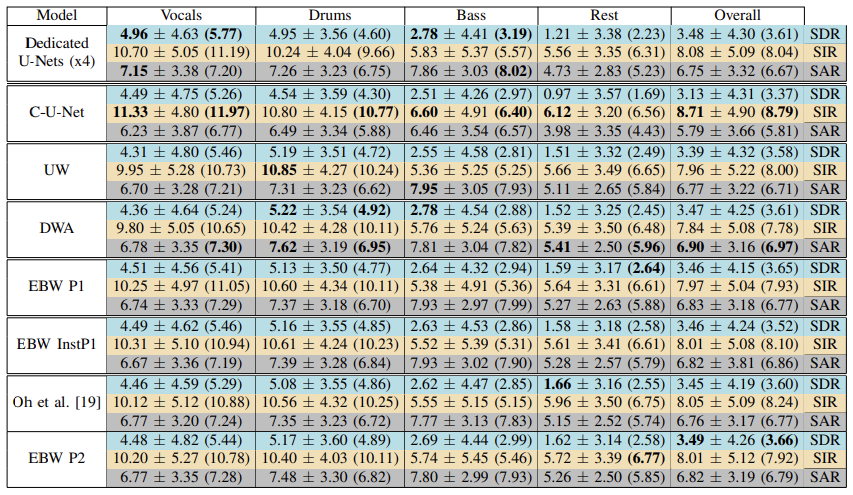
Table II. Results of Multi-instrument Source Separation Experiments
Citation
@inproceedings{kadandale2020multi, title={Multi-channel u-net for music source separation}, author={Kadandale, Venkatesh S and Montesinos, Juan F and Haro, Gloria and G{\'o}mez, Emilia}, booktitle={2020 IEEE 22nd International Workshop on Multimedia Signal Processing (MMSP)}, pages={1--6}, year={2020}, organization={IEEE} }
Acknowledgements
This work has received funding from the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska- Curie grant agreement No. 713673. V. S. K. has received financial support through “la Caixa” Foundation (ID 100010434), fellowship code: LCF/BQ/DI18/11660064. Additional funding comes from the MICINN/FEDER UE project with reference PGC2018-098625-B-I00, H2020-MSCA-RISE-2017 project with reference 777826 NoMADS, Spanish Ministry of Economy and Competitiveness under the Marı́a de Maeztu Units of Excellence Program (MDM-2015-0502) and the Social European Funds. We also thank Nvidia for the donation of GPUs.
We thank Daniel Michelsanti (Aalborg University) and Olga Slizovskaia (Universitat Pompeu Fabra) for the insightful discussions related to source separation methods and practices.